오늘은 대표적인 CNN의 구조들에 대해 살펴보려고 한다. 제안된 CNN의 구조는 다양하며, 책(밑시딥)에서는 LeNet과 AlexNet을 설명하고 있으며, 이외에도 VGGNet, GoogleNet, ResNet 등이 있다. 이번에는 전반적으로 간단하게 살펴볼 것이며, 자세한 부분은 추후 각 Paper review에서 다뤄볼 예정이다.
LeNet
먼저, LeNet에 대해 이야기 해보자. LeNet은 1990년대에 만들어진 것으로, 1~5까지 있다.
C3 Layer :앞의 6개의 Feature map에서 조합을 통해 16장의 특성맵을 얻은 조합표이다. a. (5_5_3+1)*6 = 456 b. (5_5_4+1)*9 = 909 c. (5_5_6+1)*1 = 151 d. 총 456+909+151=1516
S4 Layer : (1 + 1)*16 = 32
C5 Layer : (5_5_16 + 1)*120 =48120
F6 Layer : (120 + 1)*84 = 10164 총 156+12+1516+32+48120+10164 = 60000 개의 파라미터를 가지고 있다. 💡 현재의 CNN과 차이점이라 한다면, LeNet은 Sigmoid 함수를 이용하고, 현재는 주로 ReLU를 사용한다. 또한, LeNet은 Subsapling을, 현재는 Max-Pooling을 이용하여 데이터를 축소시킨다.
Average Pooling이란? 왜 Average Pooling을 사용했는가?
Pooling 연산을 하는 방법은 동일합니다. 만약 Max-Pooling이라 한다면 행렬 요소들의 값 중 가장 큰 값을 사용한다면, 각 요소들의 평균 값을 사용하는 것을 Average Pooling이라 합니다.
우선 Average Pooling을 사용하게 되면 비교적 덜 중요한 요소를 포함할 수 있는데 그렇게 된다면, 전체적인 분산을 이용할 수 있게된다. →즉, Object Detection 분야에서 평균과 분산의 개념을 활용하여 물체 위치를 보다 쉽게 파악할 수 있기 때문이다.
왜 Gaussian Layer를 사용했는가?
Gausian Layer는 마지막 객체를 Classification할 때 사용하는 Layer 입니다. 즉, ‘객체의 분포가 어느 위치에 있는가?’에 따라 해당 객체를 분류한다고 생각합니다.
이는 논문에서는 Gaussian Layer를 사용했다고는 하지만 논문 구현을 하는 분들은 Gaussian Layer를 사용하지 않고 Softmax 를 사용하여 Classification을 진행하고 이렇게 해도 무관하다라고 합니다.
AlexNet
2012년 개최된 ILSVRC대회에 우승을 차지 CNN 구조이다. LeNet과의 구조 크게 다르지 않지만, 2개의 GPU로 병렬 구조로 설계되었다.
AlexNet 의 구조는 다음과 같다.
Convolution Layer 5개, FC Layer 3개로 구성되어있다.
Activation Fuction으로 ReLU를 사용한다.
Why?
AlexNet 이전에는 보편적으로 사용되었던 활성함수가 tanh 함수 입니다.
ReLU를 사용하게 되면서 학습 속도가 향상됨을 볼 수 있었고, tanh과 비교했을 때, 약 7배 가까이 빨랐기 때문에 이를 사용하게 되었습니다.
그림에서 보이듯이 2,4,5번째 Convolution에서는 같은 Channel의 Feature map과 연결되어 있지만, 3번째 Convolution에서는 두 Channel 모두 연결되어 있다.
Input image가 그림에선 224로 표기되어 있지만, 오타로 227x227 size의 Input을 가진다.
1st Conv Layer
96개의 11x11x3 Size로 Convolution을 진행한다.(Stride=4, zero-padding(x)) → 55x55x48 Feature map을 두 개 가짐.(GPU가 2개 이므로 병렬 연산을 위해 2개로 나눈다.)
128개의 5x5x48 커널을 두 번 사용하여, Convolution을 진행한다.(stride=1, zero-padding=2) → 27x27x128 Feature map을 두 개 가짐.
3x3 Overlapping Max-Pooling (stride=2)로 진행 → 13x13x128x2 Feature map을 가짐.
LRN을 시행
3rd Conv Layer
384개의 3x3x256 커널을 사용하여 Convolution을 진행(두 Channel 모두와 연결되어 있어, 한 Channel 당 3x3x128x2개의 Feature map을 Convolution한다. )(stride=1, zero-padding=1) → 13x13x192x2의 Feature map을 가진다.
4th Conv Layer
192개의 3x3x192 커널을 2번 사용하여 Convolution을 함.(stride,zero-padding=1) →13x13x192x2 Feature map을 가짐
5th Conv Layer
128개의 3x3x192를 Channel 당 1번씩 2번 Convolution 해준다.(stride, zero-padding=1) → 13x13x128x2 Feature map을 가짐
6x6x256 Feature map을 Flatten 하여 1차원 9216개의 vector로 만든다.
이를 4096개의 뉴런과 Fully Connected 한다.(채널당 2048개)
7th FC Layer
동일하게 4096개의 뉴런으로 구성되어 전 단계의 4096개를 Fully Connected한다.
8th FC Layer
1000개의 뉴런으로 구성되어 4096개의 뉴런과 Fully Connected한다.
출력 값에 softmax 함수를 적용하여 1000개의 Class 에 속할 확률을 나타낸다.
Non-overlapping vs overlapping
Convolution 연산 시, 겹치게 할 것인지 혹은 겹치지 않게 할 것 인지 의미한다.
Overlapping Pooling 연산을 하게 되면 Stride 과정을 할 때 window가 겹치면서 계산되어 놓치는 부분이 Non-Overlapping Pooling에 비해 적게 됩니다. 이로 인해 정확도가 약간 향상됨을 볼 수 있습니다. 물론 단점으로는 그만큼의 연산량이 증가하게 됩니다. AlexNet의 경우 Overlapping Pooling 연산을 함으로써 약 0.4%의 정확도 향상을 얻었다고 합니다.
Local Response Normalization(LRN) 일단 AlexNet에서 사용한 LRN을 자세히 살펴보면 Local Response Normalization layer implements the lateral inhibition 한다고 합니다. 여기서 lateral inhibition(측면 억제)가 무엇인지 알아보겠습니다.측면억제는 신경생리학 용어로, 한 영역에 있는 신경 세포가 상호 간 연결되어 있을 때 한 그 자신의 축색이나 자신과 이웃 신경세를 매개하는 중간신경세포(interneuron)를 통해 이웃에 있는 신경 세포를 억제하려는 경향이라고 합니다. AlexNet에서 이러한 측면억제를 사용한 이유를 살펴보겠습니다. ReLU를 사용함으로써 ReLU의 특성인 양수값을 그대로 받아 사용하게 되어 매우 높은 pixel 값을 가지는 곳이 주변 pixel에 영향을 주게 됩니다. 이러한 부분을 방지하기 위해 주변에 있는 pixel끼리 normalization을 진행하게 됩니다.
Dropout 과적합(Overfitting) 방지를 위해 사용하는 것으로 뉴런의 일부를 생략하고 학습을 진행한다.
Data augmentation 아래의 CNN 구조들은 층이 깊어지면서 Layer 하나씩 살펴보기 보다는 각 구조의 특징들을 자세히 살펴보도록 하자. 과적합(overfitting) 방지를 위해 Data 양을 늘려 방지하고자 대칭, Crop 등과 같은 기법을 이용해 Data양을 늘렸다.
VGGNet
VGGNet은 Layer 층의 개수에 따라 VGG-16 / VGG-19로 나누어진다.
앞서 이야기한 LeNet과 AlexNet의 층은 비교적 작았지만 앞으로 보는 것들은 점점 깊은 층을 가지게 된다.
VGGNet은 오직 depth가 학습에 주는 영향력을 알기 위해 3x3 filter(stride=1)로 진행하고, 2x2 MaxPooling(stride=2)로 학습을 진행하였다.
depth가 깊어질수록 성능은 높아질 수 있지만, 파라미터가 증가하여 Overfitting이 발생할 수 있고 연산량이 많아져 학습 시간이 길어질 수 있다.
왜 3x3 Convolution 만을 사용하여 층을 쌓았을까?
우선 3x3 Convolution이 상하좌우의 개념을 모두 잡을 수 있는 가장 작은 커널입니다.
5x5 혹은 7x7 Convolution과 동일한 size의 Feature Map을 만들기 위해선 2번 혹은 3번 Convolution 연산을 해야한다. 즉, ReLU 함수를 2~3번 연산에 사용을 하게 됩니다. 1번 사용하는 것과 달리 3번을 사용하여 비선형성을 높일 수 있어 더욱 차별적으로 만들 수 있습니다.
파라미터 수를 줄여 연산량이 감소합니다. → 3x3 Convolution ⇒ $3(3^2C^2) = 27C^2$ → 7x7 Convolution ⇒ $7^2C^2 = 49C^2$ ~> 약 81%더 많다.
FC layer로 왜 4096개를 사용하는가?
아주 좋은 feature representation으로 알려져있다고 합니다.
다른 데이터에서도 feature 추출이 잘되며, 다른 Task에서도 일반화 능력이 뛰어난 것으로 알려져 있습니다.
GoogleNet
Googlenet은 총 22개으로 구성되어 있다.
GoogleNet의 주요한 특성 4가지를 살펴보도록 하자.
1x1 Convolution1x1 Convolution은 크게 3가지 장점을 가지고 있습니다.
Channel 수 조절
연산량 감소
비선형성 증가
Channel 수 조절
Convolution을 할 때, 큰 Channel을 사용을 하게 되면 파라미터 수의 증가 때문에 문제가 발생한다.
이 때, 1x1 Convolution을 이용하면, 원하는 Channel을 가지는 Feature map을 만들어 낼 수 있다.
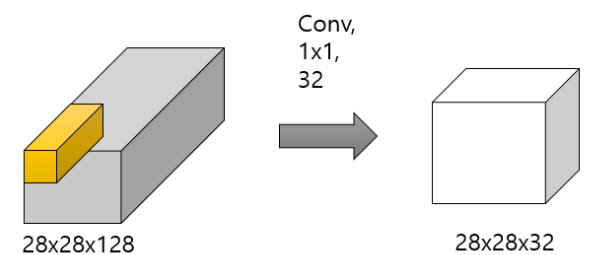
다음 그림에서 볼 수 있듯이 28x28x128 을 1x1 convolution을 통해 28x28x32로 만들어 냈다.
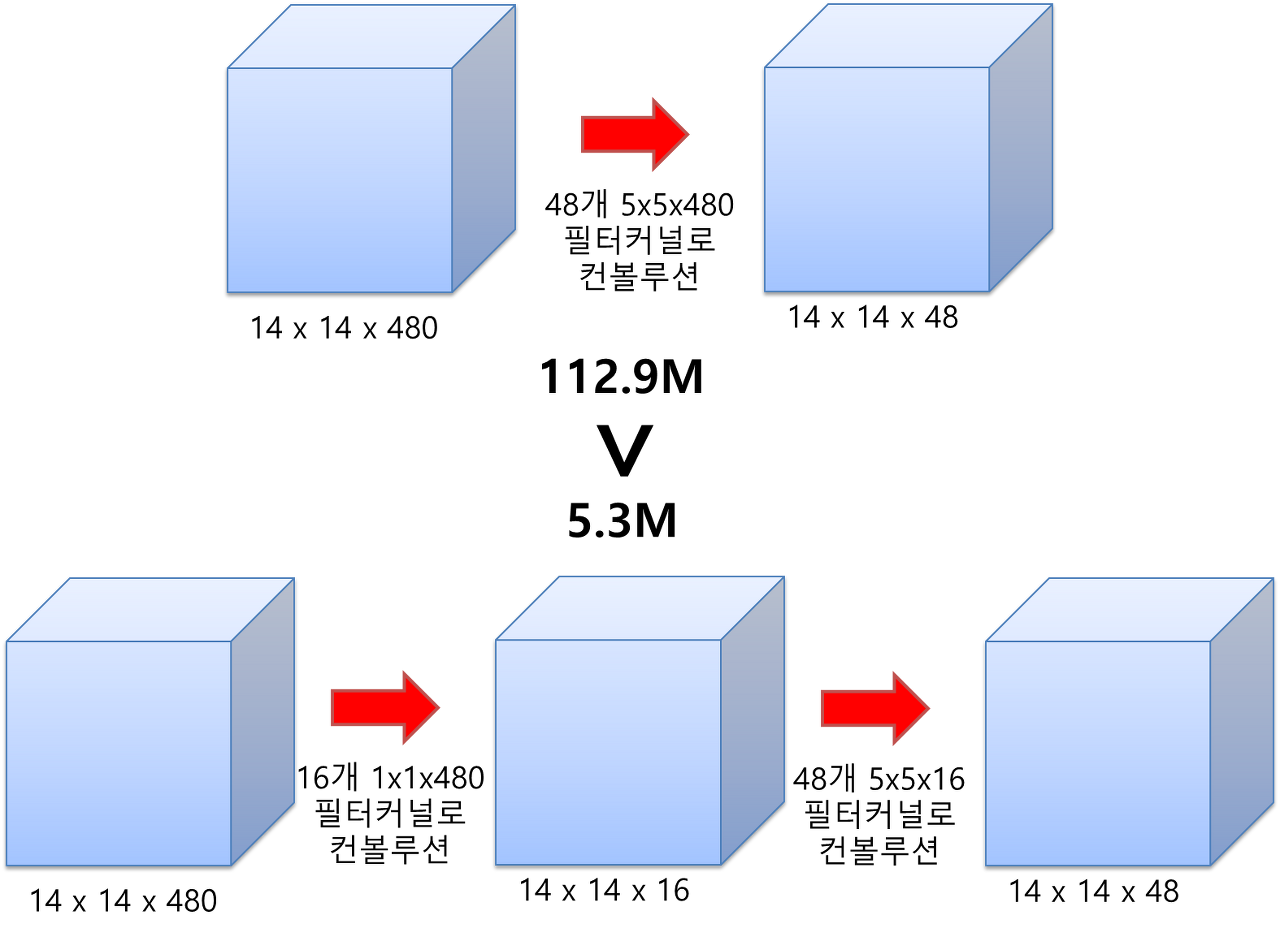
연산량 감소 다음 그림에서 확인할 수 있듯이 최종 Feature map은 14x14x48로 동일함을 볼 수 있지만 중간 1x1 Convolution이 연산량이 압도적으로 줄어듦을 확인할 수 있다.
비선형성 증가
기본적으로 Convolution을 진행할 때, 활성함수로 ReLU를 반복적으로 사용하게 되면 모델의 비선형성을 증가시켜줍니다.(ReLU를 사용하는 이유 중 하나) →모델의 패턴을 잘 인식한다.
이 때, 1x1 Convolution을 진행하게 되면 파라미터 수는 감소하게 되고, 활성함수로 ReLU를 선택하여 비선형성을 증가시킬 수 있다.
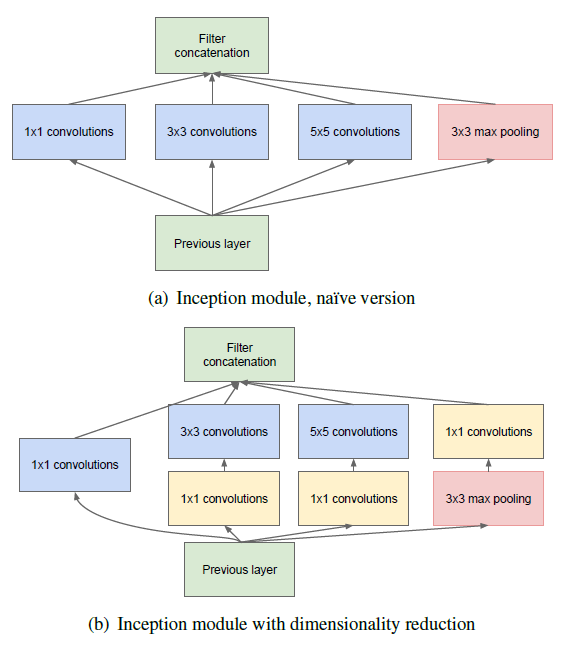
Inception Module
하나의 레이어에서 1x1, 3x3, 5,5 Convolution과 3x3 Maxpooling을 concat 해준다. → 좀 더 다양한 특성을 얻을 수 있다.
Global Average Pooling
후반부에 일반적으로는 FC layer가 있지만, GoogleNet은 Global Average Pooling을 사용했다 → 가중치의 개수가 많이 없어진다.(FC 방식 : 51.3M Global : 0) → 연산량이 줄어든다.
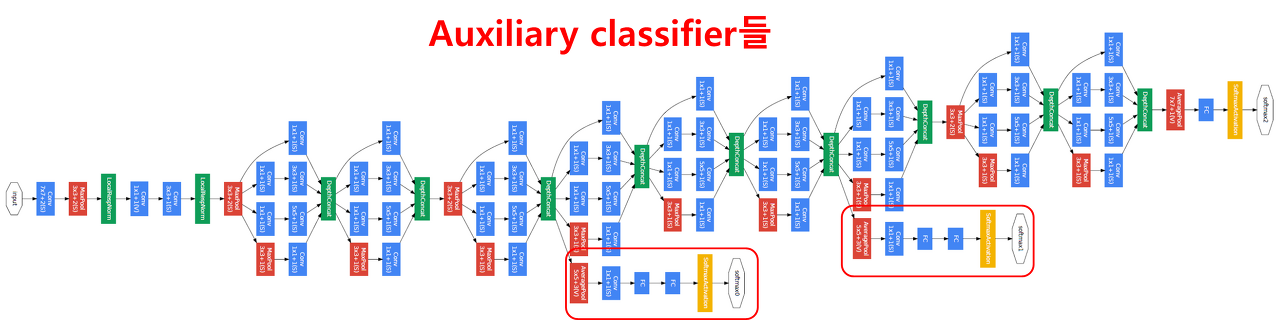
auxiliary classifier
층이 깊어지면서 생기는 Vanishing Gradient를 방지하고자 사용.
오차역전파 계산 시, weight 값에 큰 영향을 주는 것을 막기 위해 axiliary classifier에 0.3을 곱한다.
Train 할 때 발생하는 Vanishing Gradient를 방지하고자 사용하기 때문에 Test를 진행할 때는 제거하고 사용한다.
VGGNet과 같은 시기에 나와 1등을 기록했지만, 복잡한 구조로 인해 VGGNet을 더 선호해서 사용하게된다.
ResNet
ResNet도 층을 깊게하여 좋은 성능을 내고자 하는 구조이다 하지만 층을 깊게 쌓을 수록 Gradient Vanishing 문제가 발생했으며, 아래의 그림처럼 층이 깊어질 수록 학습이 잘 되지 않음을 알 수 있다.
이에 ResNet 저자들의 핵심 아이디어는 Residual Block이다.
위의 그림처럼 일종의 지름길을 만들어 Gradient Vanishing 문제를 해결하면서 층을 깊게 쌓을수 있게 되는것이다.
ResNet 원 논문에서는 이를 어떤 이론을 바탕으로 결과를 찾기보단, 경험적 바탕이 컸다.